Interviewing data: using databases
You will probably all have previously used spreadsheets to organize and analyze data. Today’s class aims to take your skills to the next level, by introducing databases and the language used to query them. Databases can handle larger datasets, and with practice are more flexible and nimble for filtering, sorting, and grouping and aggregating data.
Databases also allow you to join multiple data tables into one, or match records across different datasets, if they have common fields – which can be a powerful tool.
It often makes sense to process data in a database before exporting to the software you will use to visualize it.
Introducing SQLite and the SQLite Manager Firefox add-on
We will work with SQLite, database software that can be managed using a free add-on to the Firefox browser, called the SQLite Manager.
SQLite claims to be the most widely-used database software in the world, and is built into many software applications including Firefox — which uses it to manage information including your bookmarks. SQLite is easier to configure and work with than databases like MySQL and PostgeSQL, in which the database runs on a “server,” either on your own machine or over the Internet. Instead, SQLite databases are simple, portable files that are written directly to disk.
The SQLite Manager add-on allows you to work with any SQLite database. Open SQLite Manager by selecting Tools>SQLite Manager in Firefox. You should see a screen like this:
Data
In this class, we will work initially with data used in reporting this news story, about the drug company Pfizer’s payments to doctors. Download from here.
Later we will join World Bank data on Gross Domestic Product per capita for the world’s nations to another file for later use in mapping. Download from here.
Open database and examine its contents
Open the database pfizer.sqlite, by selecting Database>Connect Database. Navigate to the database file, and click Open.
Databases contain Tables of data. At present, this database contains only one Table, called pfizer.
Select the pfizer Table in the panel to the left, and click the Browse and Search tab in the right-hand panel. You should now be able to see the first few rows of the data in the table:
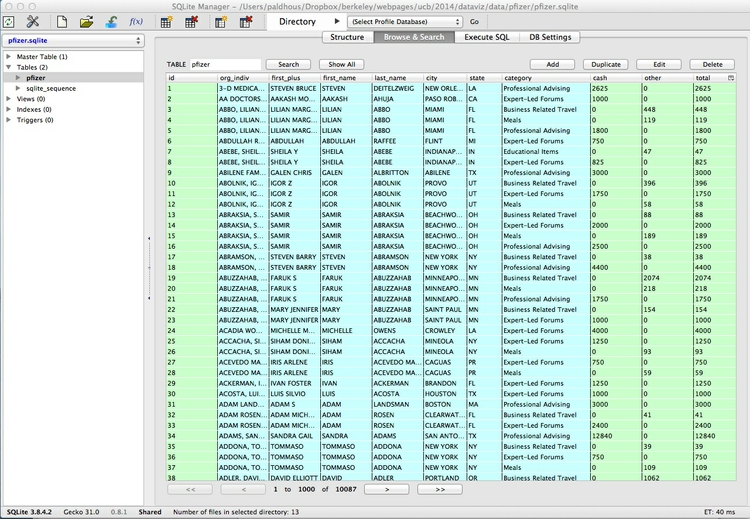
Notice that it looks much like a spreadsheet, except that columns and rows are not designated by letters and numbers in a coordinate system. Instead, the column names, called “fields” in a database, are fixed. Here each row, or “record,” has a unique ID number, created by SQLite as a “Primary Key” when the data was imported. (We will do this later with a new Table.)
Notice also that the field names are kept fairly short and have no spaces. This will keep things succinct when we write database queries. SQLite Manager also color-codes the fields by the type of data they contain: In this case numbers, which are all integers, have a light green background, while text fields are light blue. Finally, note that the total number of records is given at the foot of the Table: there are 10,087.
In this Table, each record represents the payments made in a particular category to each doctor. Individual doctors may have multiple records, if they received more than one category of payment. The text fields contain various identifying information for each doctor, while the payments are either cash or other — payments “in kind,” such as the provision of meals. The total field gives the value of payments for each record, whichever type.
Introducing Structured Query Language
To extract information from our database, we need to ask for it in the language that databases understand: Structured Query Language, or SQL. Don’t panic: The logic of SQL is very easy to follow — it is the closest that computer code comes to plain English.
Learning SQL is very useful, because (with small variations in syntax) most databases use the same language. So in this class, you won’t just be learning how to use SQLite, but also acquiring skills that can be transferred to other database software.
Write queries to filter and sort the data
Click on the Execute SQL tab and notice that Enter SQL box contains the statement SELECT * FROM tablename. Replace tablename with pfizer, and click Run SQL. That should return the entire table, because * is a wildcard that tells SQLite to return information from every field in a table. The query will return all 10,087 records, because we haven’t asked for the data to be filtered in any way.
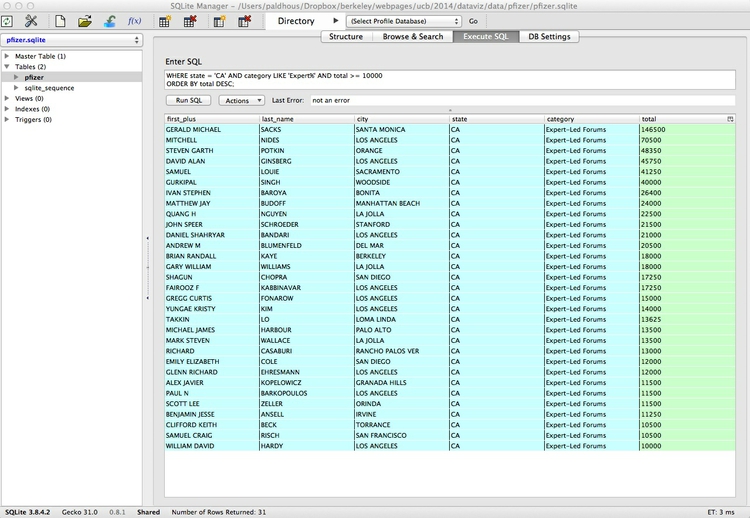
OK, now let’s run a more useful query, filtering the data to make a list of all doctors in California who were paid $10,000 or more by Pfizer to run “Expert-Led Forums,” lecturing other doctors about using the company’s drugs. Paste or type this query into the Enter box:
SELECT first_plus, last_name, city, state, category, total
FROM pfizer
WHERE state = 'CA' AND category LIKE 'Expert%' AND total >= 10000
ORDER BY total DESC;
Click Run SQL and you should see the following results:
Let’s break this query down:
SELECT first_plus, last_name, city, state, category, total
FROM pfizer
WHERE state = 'CA' AND category LIKE 'Expert%' AND total >= 10000
ORDER BY total DESC;
- The first two lines tell SQLite to
Selectthe named fields from the pfizer table, with each field separated by a comma. - The
WHEREclause applies a filter to return only certain records from the table.- When filtering text fields, the search string should be put in single quote marks.
- The second text field filter uses the operator
LIKEto perform a “fuzzy” match, and is used with wildcard characters: the%wildcard takes the place of any number of characters, while the_wildcard is used to represent single characters only. Here the%wildcard is simply saving us from having to typeExpert-Led Forumsin full, but such queries can be very useful to return data entered in slightly different ways. (LIKEalso matches irrespective of case, whereas=requires the case to be exactly as typed.) - Our query also includes a number filter, here telling SQLite to return records only when the total is greater or equal, or
>=, to 10,000. Try experimenting with different operators, such as=,<(less than), and<>(not equal to). - In this query, each part of the
WHEREclause is linked byAND, which ensures that records will only be returned if all the stated criteria are met.WHEREstatements obey Boolean logic, which uses the operatorsAND,ORandNOT; see what happens if you replace the firstANDwithOR.
- The final line of the query sorts the results in descending order by the total paid. See what happens if you remove
DESC. - The semi-colon simply marks the end of the query. See what happens if you change the end of the query to the following:
ORDER BY total DESC LIMIT 20;
Now let’s run the following query, which extends the search for doctors paid $10,000 or more for running Expert-Led Forums to New York, as well as California:
SELECT first_plus, last_name, city, state, category, total
FROM pfizer
WHERE (state = 'CA' OR state = 'NY') AND category LIKE 'Expert%' AND total >= 10000
ORDER BY total DESC;
Notice the brackets surrounding the first part of the WHERE clause: These function just like in normal algebra, ensuring that this part of the query is run first. Now remove these brackets and look at the results, so that you understand how this works.
By now you should be starting to get the hang of SQL, so let’s try a couple more queries to filter and sort the data.
1) The 20 doctors across the four largest states (CA, TX, FL, NY) paid the most for Professional Advising:
SELECT first_plus, last_name, city, category, state, total
FROM pfizer
WHERE (state = 'CA' OR state = 'TX' OR state = 'FL' OR state = 'NY') AND category LIKE 'Prof%'
ORDER BY total DESC
LIMIT 20;
It should hopefully be obvious how the LIMIT clause works.
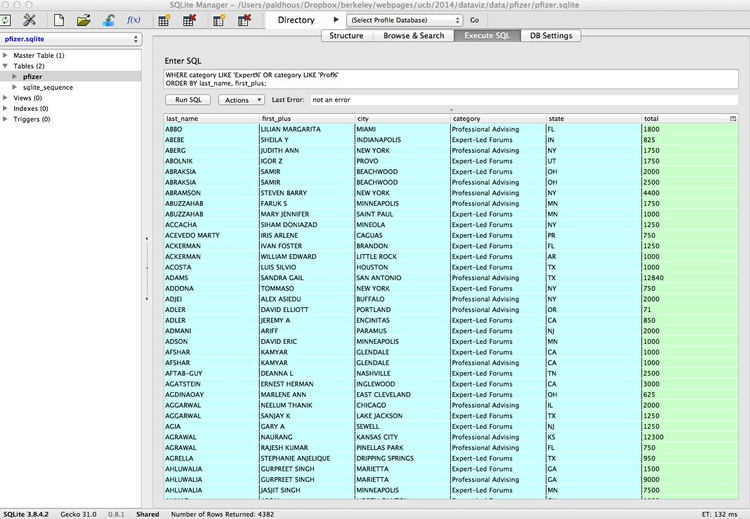
2) All payments for speaking at Expert-Led Forums or for Professional Advising, arranged alphabetically by doctor (last name, then other names):
SELECT last_name, first_plus, city, category, state, total
FROM pfizer
WHERE category LIKE 'Expert%' OR category LIKE 'Prof%'
ORDER BY last_name, first_plus;
Notice from the above that you can sort by more than one field; in this case both sorts are in the same ascending alphabetical order, but they need not be.
This should be the result of the last query:
Save and export queries
Next we will save the last of these queries, so that we can return to it later. Select View>Create View from the top menu, give the View a suitable name (e.g. speak_advice), and paste the SQL for the query into the box:
Click OK, and at the next dialog box click Yes. Double click on Views in the left panel and select the newly created View. The results of the query appear in the Browse & Search tab.
Now click on the Structure tab, which should look like this:
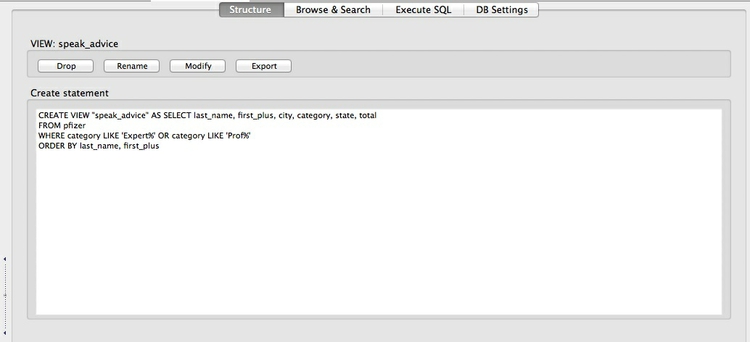
To export a query, click on Export, then fill the dialog box in as follows:
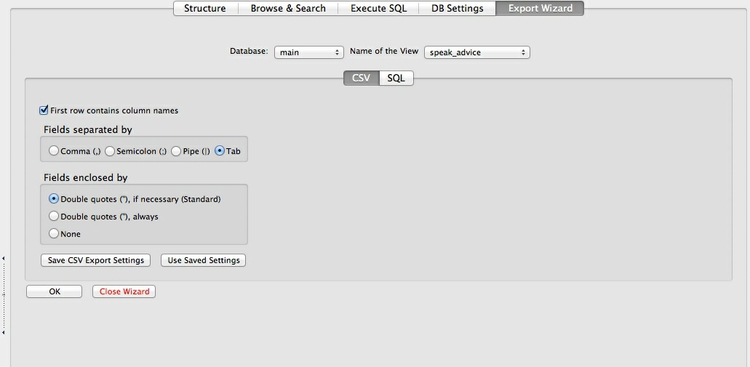
Selecting the CSV tab saves the query as a CSV or other text file. I usually save with a Tab separating the fields, to give a tab-delimited text file, like those we have used in previous weeks. Make sure to check First row contains column names; selecting Double quotes(") if necessary(Standard) will enclose all text entries in the data in double quotes.
Click OK, and save the query with a .txt suffix.
Reproducibility: databases vs. spreadsheets
By creating Views, you can keep a record of the queries you have run. This is good practice in data journalism, as it creates a reproducible record of your data processing — in stark contrast to point-and-click operations in a spreadsheet, which are hard to document.
As a data journalist, an important goal should be to maintain a fully documented trail of your work from raw data to published story or visualization. This allows data-savvy editors (if you are lucky enough to have them!) to check your work, and may be important if your conclusions or accuracy are challenged.
Write queries to group and aggregate data
Now let’s write a query to calculate the total payments made in each state. Click on the Execute SQL tab, and run the following query:
SELECT state, SUM(total) AS state_total
FROM pfizer
GROUP BY state
ORDER BY state_total DESC;
Click Run SQL and you should see the following results:
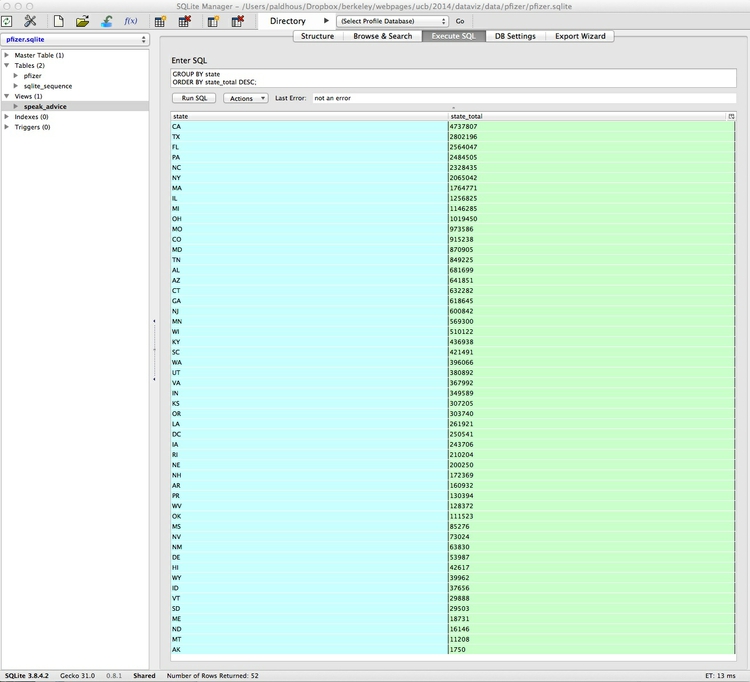
Again, let’s break this query down:
SELECT state, SUM(total) AS state_total
FROM pfizer
GROUP BY state
ORDER BY state_total DESC;
- The first two lines return data for state and total, with the totals added up using the function
SUMand the field renamedASstate_total. See what happens if you replaceSUMwithAVG,MAX,MINorCOUNT. - The third line with the
GROUP BYclause is crucial, telling SQLite how to group the data to calculate the totals. In queries like this, fields that are selected but are not themselves being aggregated (usingSUM,AVGetc) must appear in theGROUP BYclause.
Notice how the variable or field to be acted on by the SUM function appears in brackets. This is a common feature of code, which we will see crop up again in later classes.
Now let’s total by state just for payments made for Expert-led forums, using this query:
SELECT state, SUM(total) AS expert_total
FROM pfizer
GROUP BY state, category
HAVING category LIKE 'Expert%'
ORDER BY expert_total DESC;
Click Run SQL and you should see the following results:
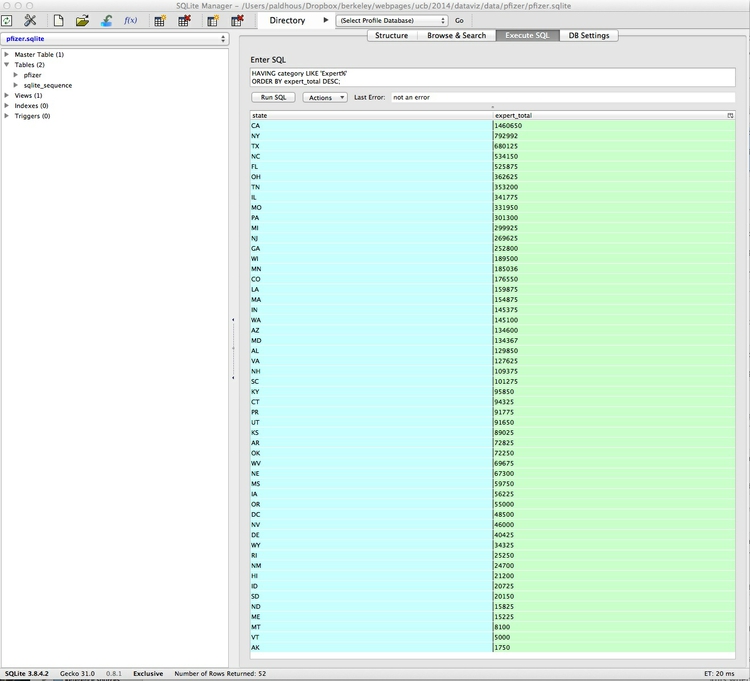
This query introduces the HAVING clause:
SELECT state, SUM(total) AS expert_total
FROM pfizer
GROUP BY state, category
HAVING category LIKE 'Expert%'
ORDER BY expert_total DESC;
For queries that include a GROUP BY clause, HAVING does the same filtering job as WHERE does in a simple filtering query; note that fields that appear in the HAVING clause must also appear under GROUP BY.
We can also aggregate data by more than one field at a time. For example, this query calculates the total payments by state and by category:
SELECT state, category, SUM(total) AS subtotal
FROM pfizer
GROUP BY state, category;
This should be the result:
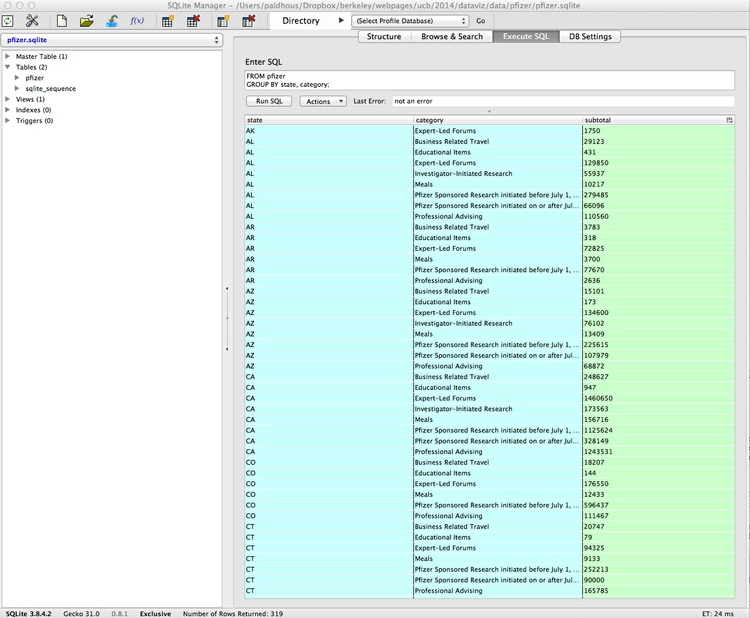
Replicate this query as a pivot table in Libre Office Calc
To human eyes, this data would be easier to read if it were in a table with the states in rows and the cateories in columns. This is sometimes called a “pivot table,” and involves converting the data from a “long” to a “wide” format. Making pivot tables, or converting between these formats for specific visualization tasks, is a common task in data journalism.
SQLite lacks a pivot function, and this is one task where a spreadsheet has an advantage. So let’s briefly put the database to one side, and import the Pfizer data, which is in the file pfizer.txt, into Libre Office Calc by selecting Insert>Sheet From File form the top menu. Save the spreadsheet, then select Data>Pivot Table>Create from the top menu, and click OK when the data is selected. At the next dialog box, drag and drop the fields as follows:
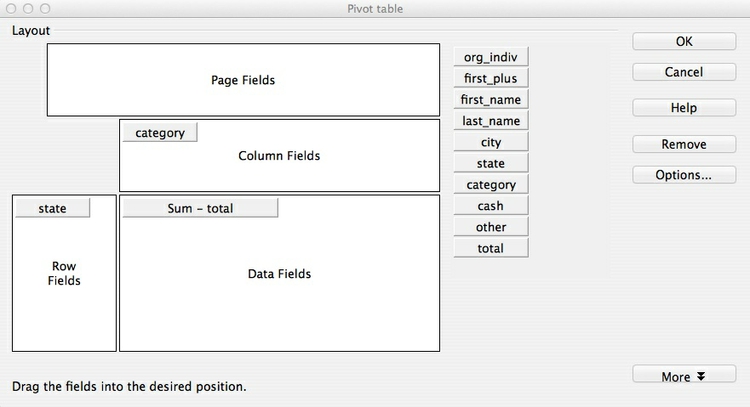
Note that the default is to aggregate the totals using Sum, which is what we want here. You can select other aggregate measures by clicking Options ....
Click OK, and this should be the result:
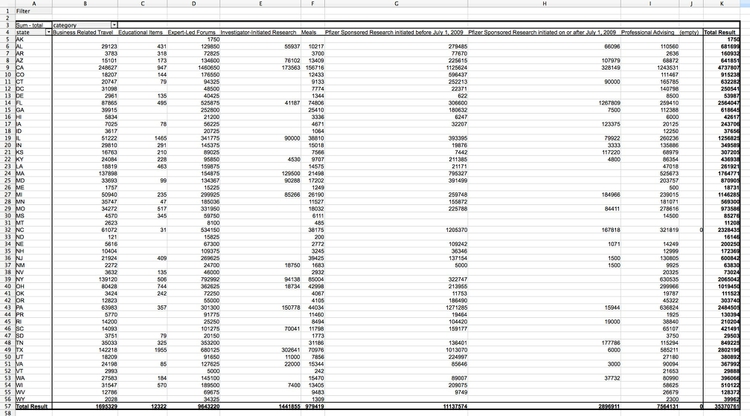
Save and close the spreadsheet, then return to the database.
Run a query on a query
We can run queries on queries that we have previously saved as Views. Let’s do that on our saved list of all payments for Expert-led Forums or Professional Advising, returning the total payments for these two categories made to each doctor:
SELECT first_plus, last_name, city, state, SUM(total) AS sum_total
FROM speak_advice
GROUP BY first_plus, last_name, city, state
ORDER BY sum_total DESC;
Notice how the name of the saved View is used in the FROM clause, where previously we named a Table.
We can also obtain the same result in one step, without saving as a View, using a subquery. This is given in brackets, indicating that it should be run before the rest of the query:
SELECT first_plus, last_name, city, state, SUM(total) AS sum_total
FROM (SELECT first_plus, last_name, city, category, state, total
FROM pfizer
WHERE category LIKE 'Expert%' OR category LIKE 'Prof%')
GROUP BY first_plus, last_name, city, state
ORDER BY sum_total DESC;
Running nested queries like this takes some practice. When starting out, you may find it easier to go step by step, saving as a View and then querying the View.
Each of these queries should give the following result:
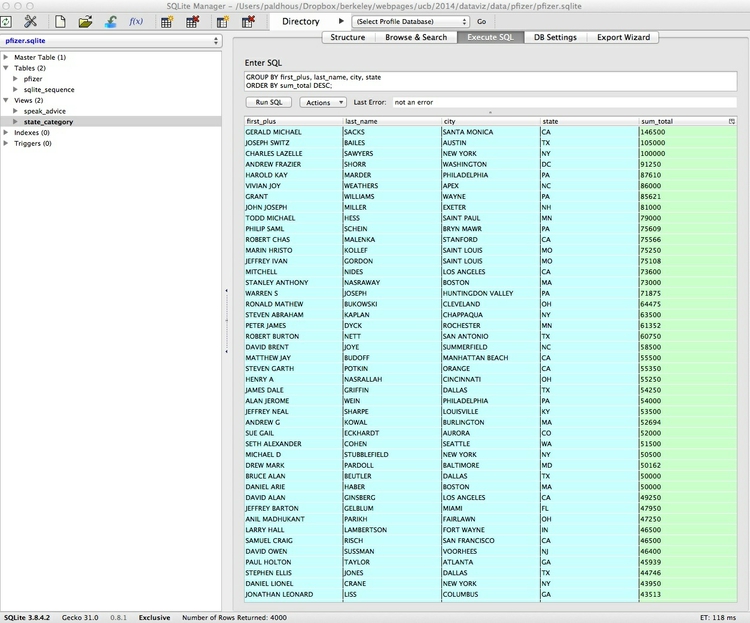
Create a new data table, and import data
Now we will create a second table and import data, in the file fda.txt, giving information about warning letters sent by the Food and Drug Administration to doctors because of problems with their conduct of clinical research on experimental drugs or medical devices.
Import the file into Libre Office Calc to view the data. The first few rows look like this when imported into a spreadsheet:
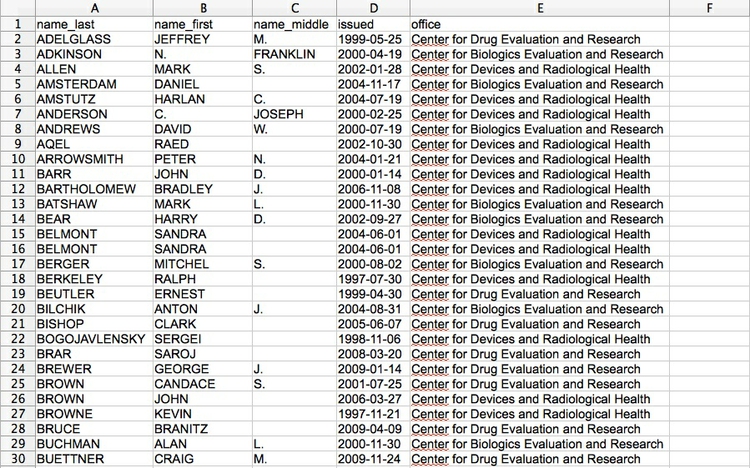
Notice that the dates are in the format YYYY-MM-DD. I strongly advise converting dates into this format for all of your data processing work, as it is an international standard, widely understood by data analysis software including SQLite. If your date also includes the time of day, use one of the following formats:
YYYY-MM-DD HH:MM:SS
YYYY-MM-DDTHH:MM:SS
In the second format T is simply the capital letter “T”, inserted into the date to note the distinction between date and time values.
Return to the database, and create a table into which to import the data. Select Table>Create Table from the top menu, and Select File. You will need to change the Format at the dialog box from CSV Files to All Files to import a file with a .txt extension.
Now fill in the import dialog box as follows:
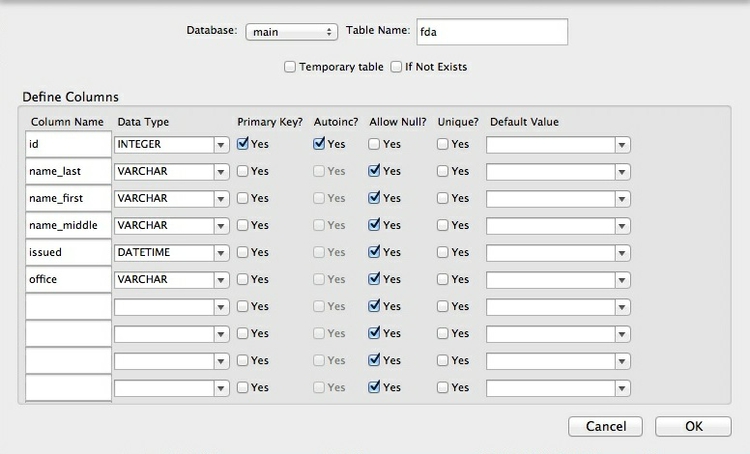
The first id field will be automatically created when the data is imported, giving a unique ID number to each record. For this field, make sure to select INTEGER for Data Type, and to check the Primary Key and Autoinc boxes.
As mentioned above, Primary Keys uniquely identify each record in a database Table. (If you are importing data that already contains a column that uniquely identifying each record, then you can select that as the Primary Key.)
The other Column Names match those in the data; take care to select the correct Data Type. VARCHAR means a text field of varying length; DATETIME should be used for the issued date. Here is a reference for Data Types accepted by SQLite.
Click Yes at the next dialog box, which will show the SQL code being used to create the table.
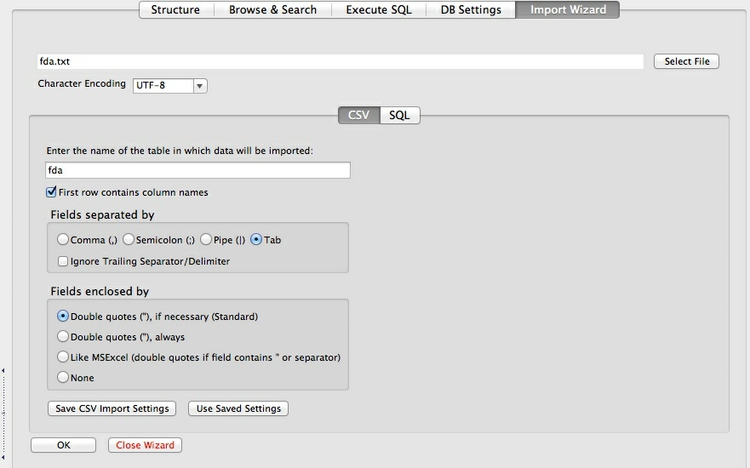
Now we can import the data, by clicking the Import icon: 
Fill in the dialog box as follows, and select OK at the subsequent prompts:
With the new fda Table selected in the left panel, select the Browse & Search tab to view the imported data:
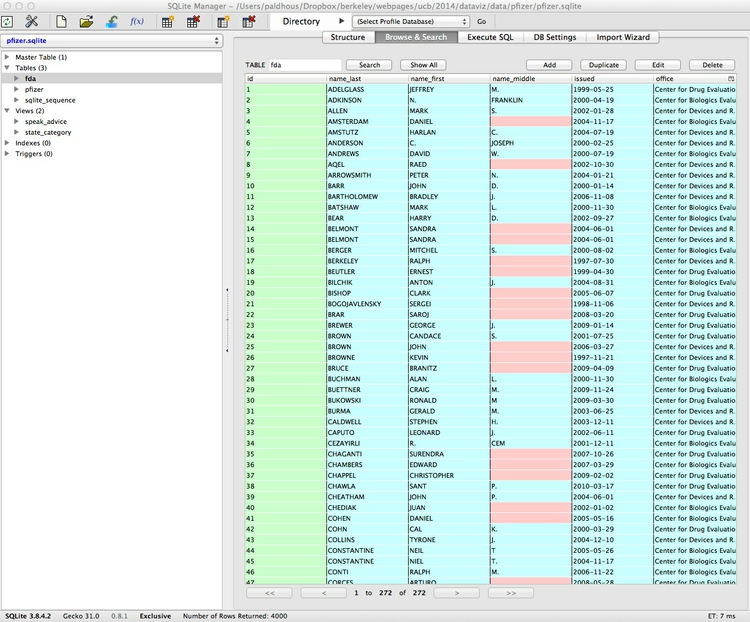
Notice that empty values, called NULLS, are color-coded in pink.
Run queries using dates
Date values are colored the same as text, and when used in queries should be put in single quote marks, as for text. For dates we can use operators that we previously used for numbers, in much the same way.
For instance, this query returns all records from the fda table with issue dates from Jan 1, 2005 onwards:
SELECT *
FROM fda
WHERE issued >= '2005-01-01'
ORDER BY issued;
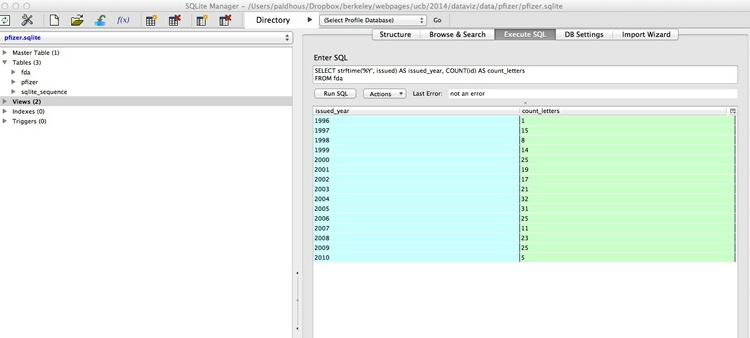
The following query uses the strftime (string from time) function to extract the year from dates, and then counts the number of letters issued per year:
SELECT strftime('%Y', issued) AS issued_year, COUNT(id) AS count_letters
FROM fda
GROUP BY issued_year
ORDER BY issued_year;
It will give the following results:
The following query illustrates other some other date functions, to return all the fields in the FDA table, with a new column showing how many days have elapsed since each letter was issued:
SELECT *, (julianday(date('now')) - julianday(issued)) AS days_elapsed
FROM fda
ORDER BY issued;
At the time of writing these class notes, this query gave the following results:
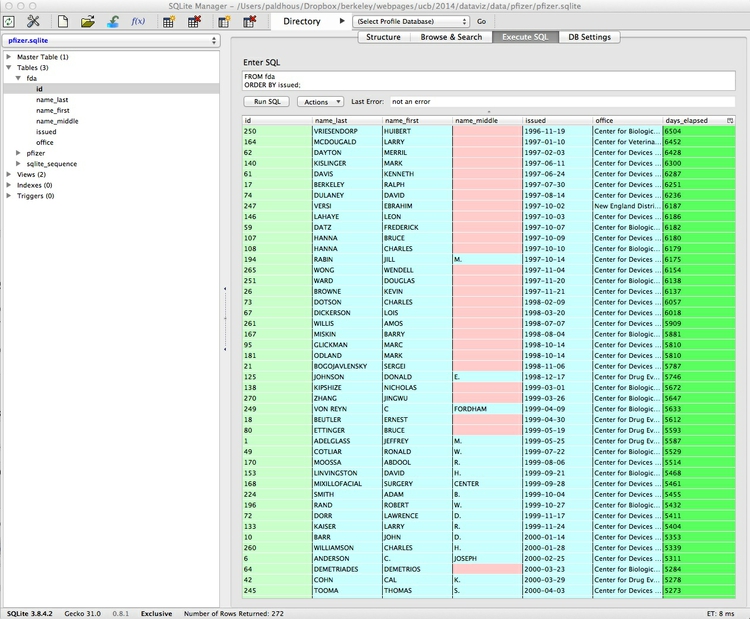
Let’s break this query down:
SELECT *, (julianday(date('now')) - julianday(issued)) AS days_elapsed
FROM fda
ORDER BY issued;
- The
juliandayfunction returns the Julian day — the number of days that have elapsed since noon in Greenwich (the Prime Meridian longitude used as a reference for time zones) on November 24, 4714 BC. Having turned dates into numbers in this way, you can subtract one from the other to calculate the difference between them in days. nowreturns the current date and time, anddateextracts just the date from this timestamp. See what happens if you run the same query without the date function.- Notice that the calculated
days_elapsedfield is color-coded in a more intense green. This is because Julian dates can be decimal fractions, so the result is “cast” by SQLite in this format, known in computing terms as a floating-point number, rather than an integer. This will be more obvious when you run the query without thedatefunction.
See here for more on querying dates with SQLite, including other periods that can be extracted from dates/times.
Query across joined data tables
Now we will run a query across our two Tables, so we select doctors paid by Pfizer to run Expert-Led Forums who had also received a warning letter from the FDA for problems with their conduct of clinical research. This involves the other main operation with data: a join.
To find doctors who may be the same individual, we need to match them by both first and last name. Here is how to achieve that using SQL:
SELECT *
FROM fda JOIN pfizer ON fda.name_last = pfizer.last_name AND fda.name_first = pfizer.first_name
WHERE pfizer.category LIKE 'Expert%';
This will give the following results:
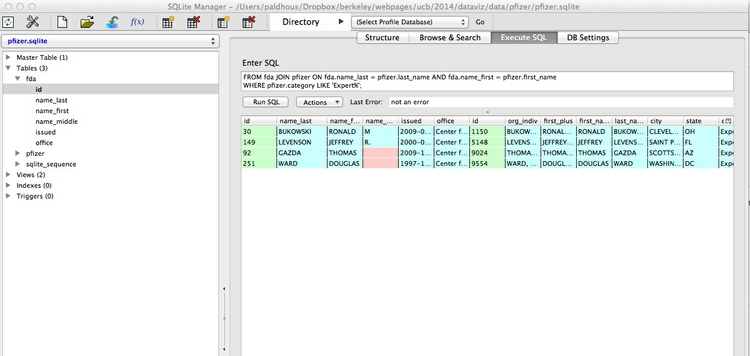
Again, let’s break this query down.
SELECT *
FROM fda JOIN pfizer ON fda.name_last = pfizer.last_name AND fda.name_first = pfizer.first_name
WHERE pfizer.category LIKE 'Expert%';
- All should be familiar apart from the
JOINwithin theFROMclause. The first part,fda JOIN pfizerspecifies the two Tables to be joined. - The rest, starting with
ON, defines how the tables should be joined together. Here we are telling SQLite to join the tables on the fields defining both firstANDlast names for each doctor. - When working with more than one table, both the table and the field can be specified, separated by a period. If any of the field names are present in both tables, you will need to do this.
The default JOIN in SQLite is called an INNER JOIN, which returns results only if there are matches across both tables. Notice that you get the same results if you write the query with INNER JOIN.
This type of query is a staple of investigative reporting, allowing reporters to match individuals across two datasets: school bus drivers and convicted sex offenders, for instance. In such cases, further reporting is needed to confirm that individuals with matching names are actually the same person!
Close the database by selecting Database>Close Database form the top menu.
Write a left join query to prepare data for mapping
In preparing data for visualization, you may want to run a different type of join query, keeping all of the data from one Table, and adding data from a second Table where there are matches, and recording fields as NULL if there is no match. This can be achieved with a LEFT JOIN, which we will illustrate by preparing some data for mapping.
First create a new database by selecting Database>New Database and saving the file with an appropriate name, such as nations_join.sqlite.
Open the file gdp_pc.txt in Libre Office Calc, which should look like this:
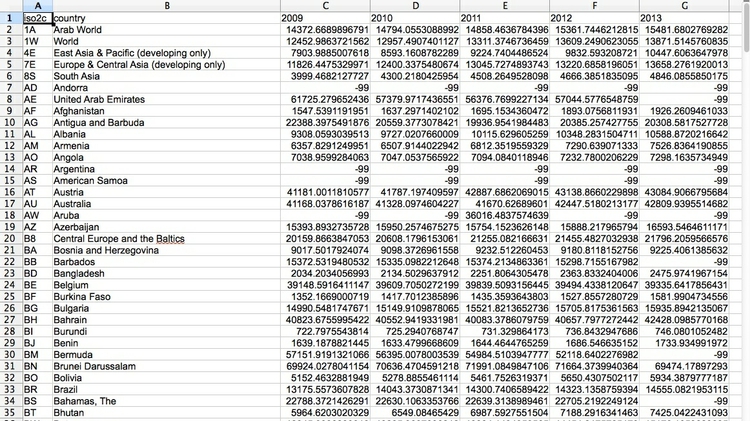
Notice that each country has a two-letter code, which we will use as the basis for the join. These are unique identifying codes for each record in the data, so can serve as a Primary Key. The columns with the year headings contain the GDP per capita data. The -99 values here represent NULL values.
This time we will skip the step of first creating a Table, as we do not need to create a new Primary Key, and simply hit the Import Icon to pull in the data. Fill in the first dialog box as follows:
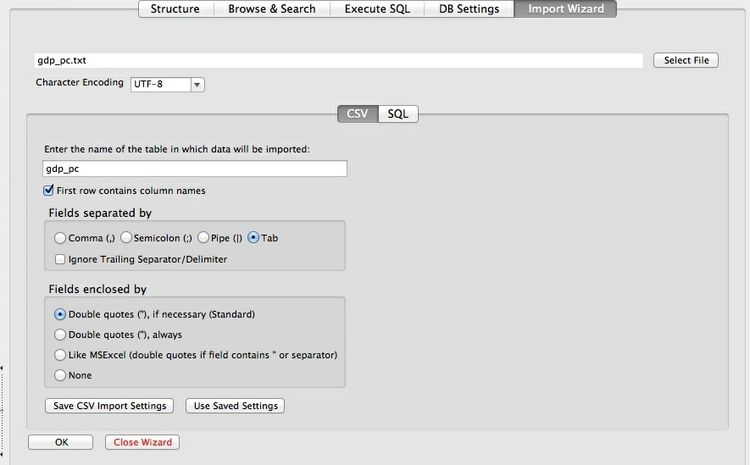
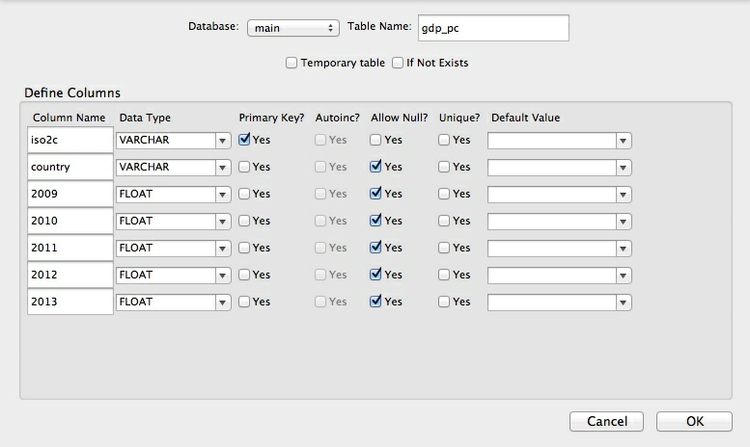
You will be asked if you want to modify the table. Click OK to do so, and select the following data types for each field. FLOAT casts the GDP per capita data as floating-point numbers, which we need as they contain decimal fractions. Notice that we have made iso2c into the Primary Key:
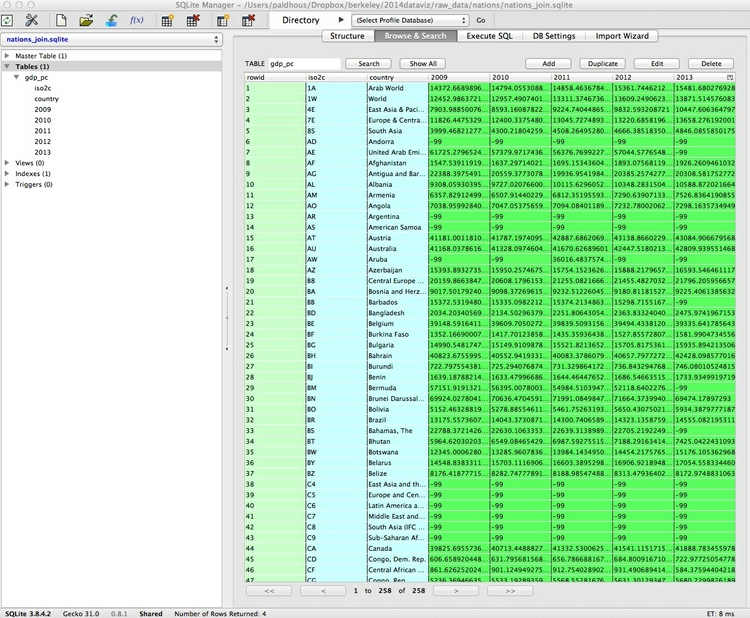
View the imported data using the Browse & Search tab:
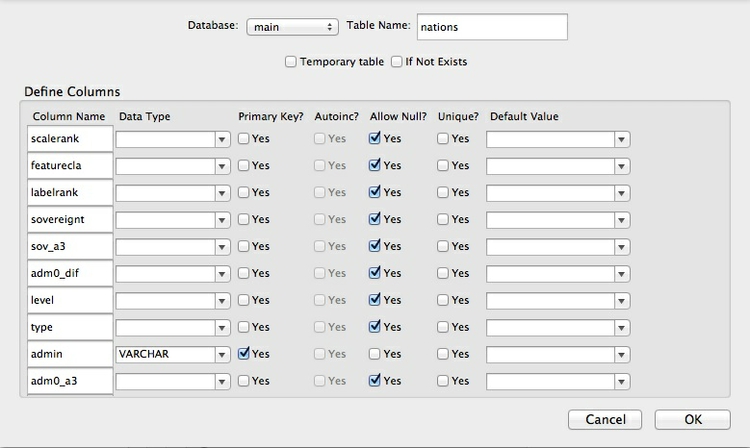
Open the file nations.txt in Calc and notice that it contains a field called iso_a2 which contains the same two-letter country codes as in the previous Table. In this case, this field is not a unique identifier for each record. However, the data also contains a field called admin, which is a unique name for each territory, and so can serve as a Primary Key.
Now import this file into SQLite. Here, we don’t need to worry about specifying the data types for each field. Instead, just ensure that admin is cast as VARCHAR and make it the Primary Key:
Now we can run this query to join all of the data from the nations Table to matching data from the gdp_pc Table:
SELECT *
FROM nations LEFT JOIN gdp_pc ON nations.iso_a2 = gdp_pc.iso2c
Save this query as a View, and export as a tab-delimited text file. Then close the database.
Finally select Database>Exit from the top menu to exit SQLite Manager.
Assignment
- Run each of the following queries in your pfizer database:
- Identify the ten doctors paid the most for Professional Advising in the state of North Carolina, giving their full name and city, and listing them in descending order of the total paid.
- Return all of the data in the FDA Table, with a new column giving the number of days elapsed from the date each letter was sent, to the end of 2010.
- Return data giving the number of FDA warning letters issued by month, irrespective of the year in which they were sent (i.e. your results should have 12 rows, which each giving the total number of letters sent in that month, from 1996 to 2010).
- Return data showing the number of FDA warning letters issued in each month for the years 2000 to 2002 inclusive (i.e you should have a separate rows for letters sent in February in 2000, 2001 and 2002). Put the results in chronological order.
- Return all fields from both tables, showing doctors who received FDA warning letters after the start of 2000, who were also paid by Pfizer for Professional Advising.
- Save each query as a View, then share your database file with me.
Some of these queries may prove quite challenging, and you may need to experiment and review SQLite’s time and date functions. If you get stuck, contact me.
Further reading
Comprehensive reference for SQL as understood by SQLite
Stack Overflow
For any work involving code, this question-and-answer site is a great resource for when you get stuck, to see how others have solved similar problems. Search the site, or browse SQLite questions.